从AKCMS4.1.8起,过滤器支持数组,下面从一个采集的实例入手讲一下这个功能是干嘛的
在采集数据时,一篇文章不仅有题目、作者、内容等一对一的数据,还有下载地址、关键词等一对多的数据。过滤器支持数组其中一个作用就能能支持对这些一对多的数据采集。以采集下载站的下载地址为例:
目标:采集http://wt.crsky.com/soft/8594.html的下载地址。
建立采集规则我们一笔带过:
采集内容块的开始:
<dl class="mirror-adr" id="dx">
采集内容块的结束:
<div class="section apprelate">
然后随便找个字段存放这个内容块的数据,比如在内容字段中写上“[field1]”
至此,已经将如图所示的部分对应的页面源代码采集到了。

但采集到的HTML中有很多不相干的标签,还有广告标签等等,与我们的目标,只采集下载地址还有很大距离,终于轮到过滤器出场了。
新建一个过滤器,内容是:
php:match('/<li class="(ie|xunlei)"><a href="(.*?)" title="允许.+?" target="_blank">.*?<\/a>/is', $input, 2);
php:implode(',',$input);
假设这个过滤器的ID是1,修改采集数据块的过滤器为1,如图:

再预览采集结果就是这样的效果:
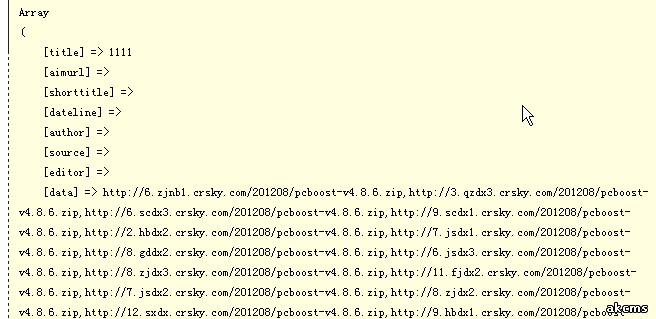
已经符合我们的要求了,再扩展一下,如果我们只采集其中的带“dx”(电信线路)的下载地址,又要怎么办呢?
再新建一个过滤器,用于过滤具体的URL,规则很简单:keep:dx
假设这个新建的过滤器的ID是2,修改原来的过滤器规则的第一条为:
php:match('/<li class="(ie|xunlei)"><a href="(.*?)" title="允许.+?" target="_blank">.*?<\/a>/is', $input, 2, 0, 2);
意思是对每一条URL使用过滤器2,预览一下可以看到不带dx两个字母的URL都过滤掉了。
再再扩展一下,如果我们要采集其中链接文字中带“山东”两个字的下载地址,又怎么办呢?
再新建一个过滤,用于过滤整个匹配的字符串,规则很简单:keep:山东
假设这个新建的过滤器ID是2,再次修改原来的过滤器规则的第一条为:
php:match('/<li class="(ie|xunlei)"><a href="(.*?)" title="允许.+?" target="_blank">.*?<\/a>/is', $input, 2,2,0);
再次预览就可以看到,只剩下两条下载地址了,不包含“山东”两个字的已经被过滤掉了。

详细解释一下:
match函数的作用是把一个字符串,用正则模式匹配一下,将所有的匹配项以字符串的形式放到一个数组中。
第一个参数的作用是:正则匹配模式(与php的preg_match_all函数的第一个参数相同)
第二个参数的作用是:传入待处理的字符串(在咱这个例子里就是采集到的下载部分的HTML代码),在过滤器中一般都是$input
第三个参数的作用是:将第几组匹配字段放入数组,这个第几组就是看你要保留的内容在第几组括号中,在咱们这个例子里就是红色部分,即第2组,与红色的2是对应的。
第四个参数的作用是:对整个匹配串使用其他过滤器,不指定就是0,即不过滤
第五个参数的作用是:对匹配到的字段使用其他过滤器,不指定就是0,即不过滤
implode的作用是用字符串把一个数组组合成一个大字符串,上面那种写法代表着用逗号把$input拼成一个长字符串。